Week 6 Outline: Web Scraping & Parsing XML
Exercise: Download XML-formatted finding aids from the Library of Congress and extract metadata fields
Open Terminal in macOS and launch our Docker container:
docker rm -f pcda_ubuntu
docker pull pcda17/ubuntu-container
docker run --name pcda_ubuntu -ti -p 8889:8889 --volume ~/Desktop/sharedfolder/:/sharedfolder/ pcda17/ubuntu-container
In Windows 10, open PowerShell and enter the following to launch the Docker container:
docker rm -f pcda_ubuntu
docker pull pcda17/ubuntu-container
docker run --name pcda_ubuntu -ti -p 8889:8889 --volume C:\Users\***username_here***\Desktop\sharedfolder:/sharedfolder/ pcda17/ubuntu-container
Open a new browser window and navigate to the Library of Congress’s list of XML finding aids by collection: http://findingaids.loc.gov/source/main.
Choose a collection you would like to work with for today’s class. For instance, the “Recorded Sound” collection is located at http://findingaids.loc.gov/source/RS. Copy the URL of the page you’ve chosen.
Navigate to localhost:8889 in your browser to open Jupyter. In the New drop-down menu new the top right of the window, select Terminal to open a bash shell session in your browser.
Make a new directory in /sharedfolder/ using the mkdir command, then cd into the directory.
mkdir LOC_Recorded_Sound
cd LOC_Recorded_Sound/
Download the LOC page you’ve chosen using wget. The --adjust-extension option adds “.html” to the end of the filename.
wget http://findingaids.loc.gov/source/RS --adjust-extension
Two more ways to download the contents of a web page:
With the page open in your browser, go to
File > Save Page As ...in the toolbar. In the window that pops up, selectWebpage, HTML Onlyas your format, then save the file wherever you like.Right click anywhere in the browser window and select
View Page Source. A new browser tab will pop up to display the page’s HTML source. Copy and paste the HTML into an empty text file.
In the macOS Finder or Windows Explorer, navigate to the sharedfolder directory on your desktop. Open the HTML file you just downloaded in Atom, or a text editor of your choice.
Scroll through the file and locate the list of links to finding aids. Each XML finding aid URL looks something like this: http://hdl.loc.gov/loc.mbrsrs/eadmbrs.rs010001.2
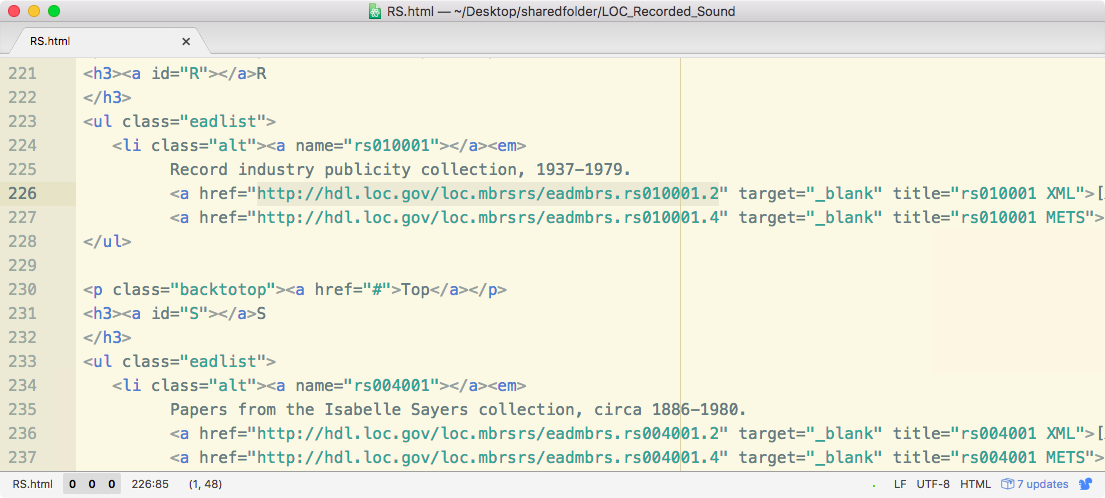
Our goal is to get each finding aid URL onto a separate line, using the text editor’s “Find and Replace” feature.
Because the same series of characters appear before and after each URL — href=" before and " target= after — use “Replace All” to replace each of these sequences with a newline.


Now save the HTML file (which is no longer proper HTML) and return to the terminal session in your browser.
We will now use the grep tool to search through the HTML file and extract lines containing URLS. The following command will write all lines in RS.html that include “http” to a new file called url_list_1.txt.
grep "http://" RS.html > url_list_1.txt
Open url_list_1.txt in your text editor and take a look. Note that the file still contains lines we don’t need, including links to METS records, which end in .4. Since all finding aid URLs that we want end in .2, we can use grep again to extract just those URLs.
grep "\.2" url_list_1.txt > url_list_2.txt
Note that the . character in our grep search term needs to be escaped using a backslash.
Open url_list_2.txt in your text editor. If the file still contains any text other than the URLs we want, delete it by hand and save the file.
Now we’re ready to download our collection of XML finding aids with wget. The -i option specifies that we want to download the files at every URL in a text file, with one URL per line.
wget -i url_list_2.txt
Navigate Jupyter Home at http://localhost:8889 and create a new Python 3 notebook.
In the first cell of your notebook, the following commands will change your working directory to /sharedfolder/LOC_Recorded_Sound and display a list of filenames in the directory.
import os
os.chdir('/sharedfolder/LOC_Recorded_Sound')
os.listdir('./')
Next we will use the BeautifulSoup package to parse an XML file. Insert one of your XML filenames in the snippet below and run it.
from bs4 import BeautifulSoup
xml_filename = 'eadmbrs.rs009003.2'
xml_text = open(xml_filename).read()
soup = BeautifulSoup(xml_text, 'lxml')
Open the same file in your text editor. Notice the tree structure of the XML file, in which each level of the XML tree is indented further than the one above it.
In case you’re working with a XML or HTML file that isn’t so neatly organized, this snippet will display a prettified version of the file.
from pprint import pprint
pprint(soup.prettify())
The following will locate the author element in the XML tree and display its contents.
author = soup.ead.filedesc.titlestmt.author.get_text()
print(author)
Or, more succinctly:
author = soup.find('author').get_text()
print(author)
The following snippet will print the author field for each file in your collection of finding aids:
for filename in [item for item in os.listdir('./') if item[-2:]=='.2']:
page = open(filename).read()
soup = BeautifulSoup(page, 'lxml')
title = soup.title.string
author = soup.find('author').get_text()
print(author)
If an XML element type appears multiple times in a file, use soup.findAll() to return them in a list:
titles = soup.findAll('title')
print(titles)
To extract text from each element, you can use a for loop or, as below, a list comprehension:
titles = [item.get_text() for item in soup.findAll('title')]
print(titles)
Crossref API
Crossref API format:
https://search.crossref.org/dois?q=10.5555%2F12345678